Il file robots.txt cos’è e a cosa serve?
Il file robots.txt è un semplice file di testo contenente delle stringhe, le quali servono per poter dare delle indicazioni ai motori di ricerca e comunicare quindi con essi.
Infatti, potresti utilizzare questo file per indicare la sitemap.xml del tuo sito web.
Questo file può essere creato e quindi editato utilizzando un qualsiasi editor di testo, come ad esempio il blocco note di Windows.
La sintassi è molto semplice in quanto deve essere facilmente leggibile dai bot, conosciuti anche come crawler, che lo visitano.
Esso contiene le linee guida per una corretta e veloce scansione delle pagine di un sito web.
Attenzione però: è sconsigliato l’utilizzo del file robots.txt per celare una pagina web o articoli dai risultati di ricerca, piuttosto, se usi WordPress installa il plugin Yoast SEO, il quale tra le sue funzionalità permette proprio di nascondere determinati contenuti.
Usando un plugin del genere, puoi infatti impostare il meta tag noindex nella sezione head di una specifica pagina.
Devi sapere infatti che alcuni bot vanno alla ricerca del file robots.txt, scansionanano ogni direttiva disallow in essa contenuta in modo da eseguire uno scraping de tuo sito alla ricerca di informazioni che non vorresti condividere.
La scrittura del file robots.txt
La prima cosa da fare è definire un user-agent, ovvero il nome del robot.
Specificando l’user-agent abbiamo infatti la possibilità di dialogare specificatamente con un particolare motore di ricerca.
Tuttavia, nella stragrande maggioranza parte dei casi, viene utilizzato il simbolo *, in modo tale che la regola verrà letta da tutti i principali motori di ricerca:
User-agent: *
Disallow:
Invece, inserendo l’user-agent Googlebot, la regola varrà solo per Google e non per gli altri motori di ricerca:
User-agent: Googlebot
Disallow:
Di seguito una lista dei principali motori di ricerca e dei loro user-agent.
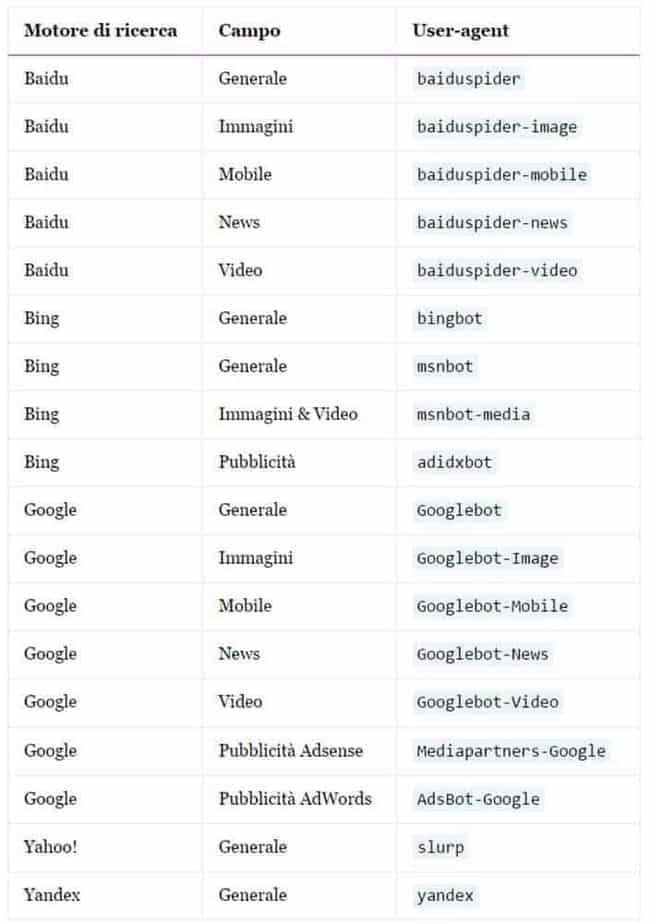
Il comando disallow del file robots.txt
Dopo aver elencato i pricipali user agenti, è bene sottolineare anche l’importanza del comando disallow.
Ebbene, esso serve ad indicare che determinate pagine o file, non devono essere considerati, qualora presenti nella stringa.
Possiamo pertanto utilizzare questo comando in questo modo:
User-agent: *
Disallow: /
oppure:
User-agent: *
Disallow: /immagini
Nel primo caso, quindi indicando semplicemente lo / senza altre indicazioni, stiamo comunicando al motore di ricerca che non abbiamo definito alcun contenuto “da evitare” e quindi tutto quanto presente nella radice del sito può essere indicizzato.
Nel secondo caso invece, stiamo specificando che la cartella o directory “immagini” non deve essere indicizzata.
Dato che abbiamo usato per entrambi gli esempi, il simbolo * nell’user-agent, queste regole verranno applicate a tutti i motori di ricerca.
Ricordati inoltre, come già menzionato prima, di non utilizzare questo comando per nascondere interi articoli o pagine.
Detto ciò, nel digitare il nome delle cartelle o delle pagine da evitare, fai sempre attenzione alla sintassi.
Rispetta dunque maiuscole e minuscole in modo da non confondere il robots (la parola “Immagini” non è quindi la stessa cosa di “immagini”).
Vogliamo chiudere questo trafiletto dandoti qualche altro consiglio utile.
Mantenendo come riferimento sempre l’esempio della folder immagini, un’altra regola che potresti decidere di impostare è quella di non passare a visitare determinati tipi di estensioni, quali ad esempio i file .jpg.
Per fare ciò, ti basterà semplicemente scrivere il tutto in questo modo:
User-agent: *
Disallow: /immagini/*jpg
Dove si trova o dove va inserito il file robots.txt?
Dopo aver creato il file robots.txt, dovrai quindi posizionarlo nella root principale del sito, ossia la directory radice.
La posizione tipo sarà dunque la seguente:
www.nomedominio.it/robots.txt
Per verificare la corretta collocazione del file, basta aprire il tuo browser e digitare nella barra di ricerca il seguente indirizzo:
www.nomedominio.it/robots.txt
Generare il contenuto del file robots.txt
Qualora volessi generare il file robots.txt in maniera più agevole, ti segnaliamo inoltre alcuni tool che potrebbero sicuramente tornarti utili.
Ecco una lista veloce di quelli più popolari:
https://toolset.mrw.it/seo/genera-robots-txt.html
https://en.ryte.com/free-tools/robots-txt-generator
https://smallseotools.com/it/robots-txt-generator
https://www.analisiseo.org/it/robots-txt-generator
Il file robots.txt e la Search Console di Google
Dopo aver editato correttamente e posizionato il file robots.txt nella radice del sito, collegati agli strumenti per Webmaster di Google, ovvero la nuova Search Console.
Registra quindi il tuo progetto all’interno di questo strumento, al fine di accertarne la proprietà, quindi scansiona il file robots.txt, mediante il Tester dei file robots.txt.


